- AI
- Productivity
J'ai arrêté de gérer mes notes. Elles se gèrent toutes seules.
J'ai enterré trois systèmes de notes. À chaque fois, le même cycle : enthousiasme, usine à gaz, déclin lent, abandon. Ce qui a tout changé : intégrer des agents IA dans la boucle. Pas par effet de mode, mais parce que les agents règlent le problème de fond.

Confession : j’ai enterré trois systèmes de notes.
Evernote en 2015 : 10 000 notes, la plupart jamais rouvertes. Roam en 2020 : un labyrinthe de liens tellement dense que retrouver quoi que ce soit prenait vingt minutes. Notion en 2022 : des dashboards tellement beaux que j’en avais oublié qu’ils devaient servir à quelque chose.
À chaque fois, le même cycle : enthousiasme, usine à gaz, déclin lent, abandon.
Je ne suis pas le seul. Le podcast a16z a tapé juste :
Parmi tous les influenceurs qui parlent de PKM, étonnamment peu ont écrit un bon livre, gagné un Emmy ou accompli quoi que ce soit de notable avec leurs systèmes. L’usage principal semble être de parler de son système.
Violent. Mais vrai.
Le problème, ce n’est pas le manque de fonctionnalités. C’est que ranger ne crée pas de valeur. Même parfaitement étiquetées, vos notes restent inertes. Et un système qui ne s’entretient pas tout seul finit par s’effondrer — pile au moment où vous êtes trop débordé pour vous en occuper. (Une étude APQC montre que les knowledge workers perdent près de 3 heures par semaine rien qu’à chercher de l’info, et plus de 8 heures au total en frictions. Ce n’est pas un problème d’outil, c’est un problème de maintenance.)
Steph Ango, le CEO d’Obsidian, a reformulé tout cela parfaitement :
Je n’ai jamais aimé le terme “second brain” parce qu’il sonne externalisé et passif. Idéalement, Obsidian devrait donner la sensation d’enfiler son exosquelette : une extension directe de soi.
Pas du stockage. Une extension. Pas une archive passive. Un partenaire actif.
Ce qui a tout changé pour moi : intégrer des agents IA dans la boucle.
Pas par effet de mode, mais parce que les agents règlent le problème de fond. Quand une IA peut interagir avec vos notes, mettre à jour vos contextes et faire remonter des connexions oubliées, il se passe quelque chose d’intéressant. Le système se met à capitaliser au lieu de péricliter.
Dan Shipper appelle ça le « compound engineering » : construire des systèmes où chaque feature rend la suivante plus facile à développer. Appliqué au savoir : documentez ce qui marche, réinjectez les leçons dans vos agents, laissez la connaissance s’accumuler au lieu de se disperser.
Cet article n’est pas un tuto. Que vous utilisiez Obsidian, Notion ou des fichiers texte, peu importe. Ce qui compte, c’est l’architecture qui permet à n’importe quel outil de fonctionner avec l’IA. C’est ça que je veux partager.
Trois hérésies
Avant d’entrer dans le vif du sujet, voici trois croyances que j’ai dû abandonner :
1. L’injection de contexte bat la recherche.
Le monde du PKM est obsédé par la recherche : meilleurs embeddings, pipelines RAG plus malins, vector stores plus sophistiqués. J’ai pris le chemin inverse : donner aux agents le bon contexte avant qu’ils aient besoin de chercher. Des fichiers CLAUDE.md à chaque niveau font que l’agent démarre en connaissant mes conventions, mes projets en cours, mes contraintes. La plupart des sessions ne déclenchent jamais de recherche. La meilleure requête, c’est celle qu’on n’a pas à faire.
2. Le meilleur système de notes est celui qu’on n’organise pas.
Si vous passez du temps à ranger votre base de connaissances à la main, c’est que le système vous fait défaut. Je n’organise pas mes notes. Les agents s’en chargent. Ils trient ma boîte de réception, mettent à jour les contextes projet, signalent ce qui est périmé et font remonter les connexions. Mon job, c’est de réfléchir et de capturer. Pas de classer.
3. Les outils sont la partie la moins intéressante.
Tous les articles PKM commencent par des comparatifs d’outils. Pas celui-ci. L’architecture compte ; le logiciel, non. Le mien se trouve être Obsidian + Git + Claude, mais on pourrait construire les mêmes patterns sur n’importe quoi qui stocke du texte brut.
La stack (volontairement basique)

| Couche | Quoi |
|---|---|
| Stockage | Vault Obsidian (markdown + dossiers) |
| Versioning | Git (chaque modif tracée, rollback sur tout) |
| Interface agent | Claude Code (CLI) + Telegram (conversationnel) |
| Orchestration | OpenClaw — le seul truc ici qui ne soit pas volontairement basique |
| Intégrations | Readwise, Calendrier, Plaud, n8n pour l’automatisation |
C’est tout. Pas d’infra complexe. Pas de pipeline d’embeddings maison. Pas de vector database.
Andrej Karpathy a observé chez Tesla : à mesure que les réseaux de neurones grossissaient, le code traditionnel disparaissait — « la stack software 2.0 a littéralement bouffé la stack logicielle ». Les modèles d’IA modernes travaillent directement avec le filesystem. Claude Code utilise des commandes bash (find, grep) plutôt que des systèmes de retrieval complexes. Le simple bat le malin.
Philosophie : chaque outil doit mériter sa place. Le versioning Git me permet de rollback n’importe quand. Cette approche conservatrice n’est pas sexy, mais c’est la base qui rend tout le reste possible.
L’architecture
second-brain/
├── inbox/ # Capturer d'abord, trier après
├── projects/ # Travail actif avec deadlines
├── knowledge/ # Notes de référence durables
├── crm/ # Personnes et organisations
├── playbook/ # Patterns réutilisables (mon levier)
├── logs/ # Résumés quotidiens, meetings
└── Readwise/ # Livres, podcasts, highlightsRien de révolutionnaire. Cal Newport prévenait :
Si je dois lancer un truc et utiliser du markup pour sauvegarder un article sur lequel je suis tombé par hasard… je vais probablement laisser tomber.
La friction minimale gagne à la capture.
Le pattern projet
Chaque dossier projet suit la même structure à trois fichiers :
- README.md — C’est quoi ? Pourquoi ça existe ? (stable)
- CONTEXT.md — Photo actuelle pour les agents (max 200 lignes, màj automatique)
- LOG.md — Historique complet (append-only, jamais édité)
Cette séparation est cruciale. Le README donne la vue d’ensemble. Le CONTEXT dit à l’agent ce qui compte là maintenant. Le LOG garde tout sans polluer le contexte de travail.
Huit projets, cinq sous-projets, seize CONTEXTs dans le vault. Tous mis à jour par les agents chaque nuit pendant que je dors.
L’ingrédient secret : les fichiers de contexte agent

C’est là que ça devient intéressant.
À chaque nouvelle session Claude, l’agent débarque à froid. Il ne connaît ni mes conventions, ni mes contraintes, ni ce sur quoi je travaillais hier. Sans contexte, il gaspille des tokens à redécouvrir des éléments que j’ai déjà compris.
La solution : des fichiers CLAUDE.md à chaque niveau.
second-brain/
├── CLAUDE.md # Racine : conventions globales
├── projects/
│ ├── CLAUDE.md # Scope : comment travailler sur les projets
│ └── my-project/
│ └── CLAUDE.md # Instance : ce projet précisL’agent lit le CLAUDE.md le plus proche d’abord, puis remonte vers les parents. Le niveau racine fournit une carte « juste-à-temps » : des pointeurs vers la doc plus profonde plutôt que des pavés de texte.
Le principe derrière le compound engineering : traiter l’IA comme un coéquipier, pas comme une boîte noire. L’onboarder. Les fichiers CLAUDE.md sont l’onboarding. Ils disent à l’agent ce qui est différent dans ce scope, quelles commandes marchent ici, quels anti-patterns éviter. (L’insight de Dan Shipper : « 80% du compound engineering se situe dans le plan et la review. » La doc est le levier.)
L’effet composé :
- Chaque session, les agents lisent un CLAUDE.md frais → productifs direct
- Chaque soir, les routines mettent à jour les CONTEXTs → demain part avec un meilleur contexte
- Chaque semaine, les patterns sont distillés → le playbook grossit
- Chaque primitive réduit la charge cognitive future → intérêts composés
La doc n’est pas un livrable one-shot. Elle vit.
La couche d’orchestration
L’architecture ne tient que parce que des routines automatisées la maintiennent en vie.
Quelqu’un doit exécuter la maintenance (penser à lancer les scripts, déclencher les workflows à la main). Si ce quelqu’un c’est vous, le système se dégrade dès que vous êtes débordé.
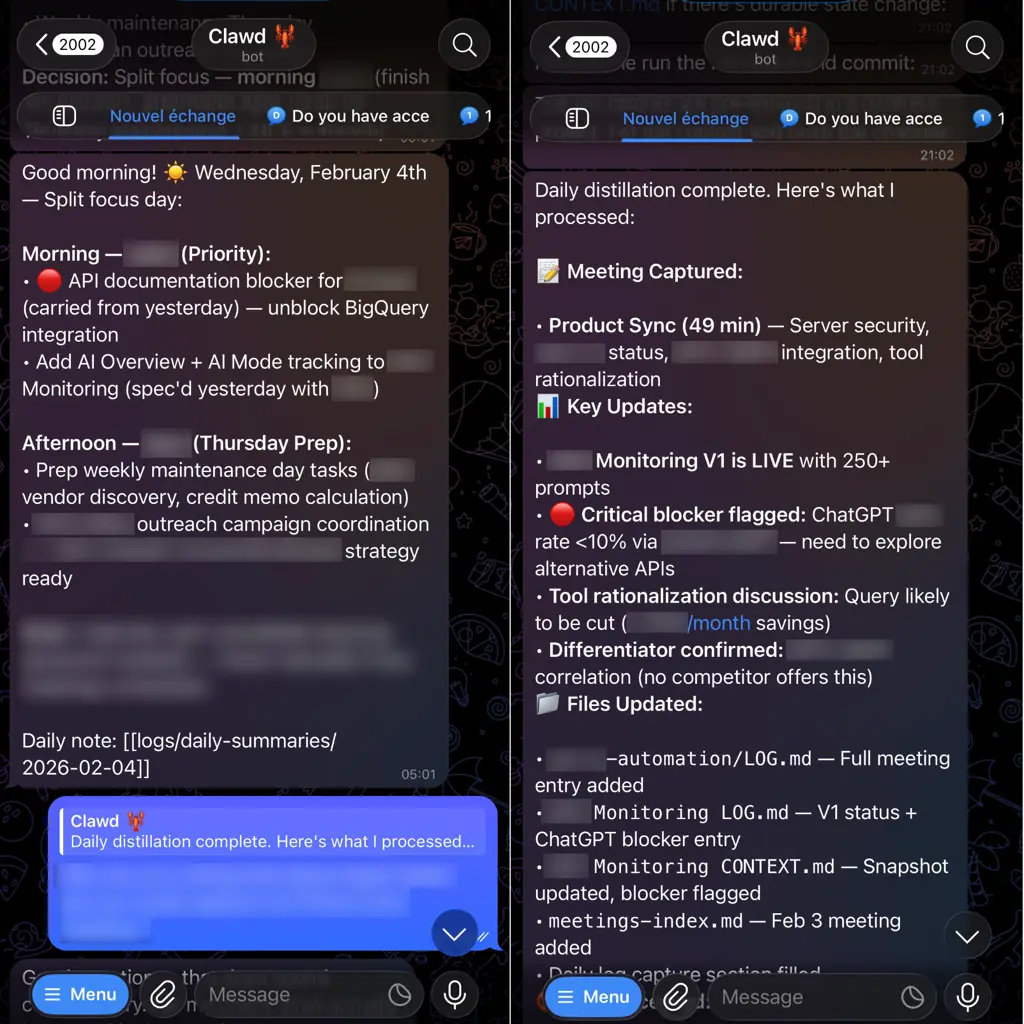
Ma solution : OpenClaw (ex MoltBot, ex ClawdBot). Si vous avez suivi l’actu des outils IA ce mois-ci, vous connaissez. Plus de 150 stars GitHub et ça grimpe. Je vais être honnête : tout le reste de cette stack est volontairement banal. Markdown. Git. Dossiers. Mais OpenClaw ? C’est là que je m’autorise à être vraiment enthousiaste.
Ce framework ouvre la voie à quelque chose de profond. MoltBook, où des agents collaborent avec une intervention humaine minimale, pourrait bien être le lieu des prochaines percées scientifiques. J’y crois.
Mais pour mon second brain, j’ai posé une limite : je suis le seul humain dans la boucle. Chaque output passe par moi avant d’aller vers qui que ce soit. Pas parce que je suis sceptique sur la collaboration multi-agents (au contraire). C’est parce que ce vault contient ma vraie vie. La valeur vient de l’intégration profonde avec des données sensibles, et cette intégration demande une confiance que j’ai construite en gardant la relation 1:1.
Le paradoxe : une instance sandboxée sans accès aux données perso serait « plus safe », et suffisamment ennuyeuse pour être abandonnée en une semaine. J’ai choisi la profondeur.
Voici ce qu’OpenClaw gère concrètement :
- Cron scheduling — Les routines daily/weekly tournent automatiquement, en sessions isolées
- Interface conversationnelle — Je parle à ma base de savoir via Telegram (texte + notes vocales)
- Recherche mémoire — Le search hybride natif d’OpenClaw (vecteurs + keywords)
- Injection de workspace — À chaque session, l’agent se réveille avec les fichiers de contexte préchargés
- Heartbeats — Polling en background toutes les ~30 minutes pour les tâches de maintenance
L’interface conversationnelle compte plus que je ne l’aurais cru. Mon interaction principale passe par Telegram : requêtes rapides en texte, notes vocales en marchant. Le second brain n’est pas une archive passive. C’est un partenaire à qui je peux parler depuis mon téléphone.
La description d’a16z d’un « vrai second brain » (vos pensées passées réinjectées dans votre esprit de travail) ne fonctionne que si la récupération est sans friction. Taper un message ou laisser une note vocale, c’est sans friction.
Les routines :
| Quand | Quoi |
|---|---|
| 06:00 | Lecture des CONTEXTs, check du calendrier, génération des priorités |
| 21:00 | Ingestion notes vocales + enregistrements meetings, màj LOGs/CONTEXTs, tri inbox |
| Samedi | Health checks, promotion mémoire, refacto des skills |
| ~30 min | Heartbeat : âge de l’inbox, scan des orphelins, alertes proactives |
Le truc des enregistrements de meetings : Plaud n’a pas d’API publique, alors j’ai reverse-engineeré l’API de leur webapp et j’en ai fait un skill agent pour OpenClaw. Maintenant mes agents récupèrent les enregistrements chaque soir, extraient les actions et classent les résumés dans les bons dossiers projet. (J’ai aussi publié des nodes n8n pour ceux qui préfèrent cette voie.) Quand un outil n’existe pas, on le construit avec Claude Code.
Sam Corcos dans Never Enough : « Créez des frictions pour que ce soit vraiment pénible de faire » ce qu’on ne devrait pas. Les routines sont l’inverse : des frictions qui rendent les bonnes habitudes automatiques.
Ce qui capitalise

Le calcul est simple :
- Chaque session : L’agent lit un CLAUDE.md frais → productif direct
- Chaque clôture : Les contextes sont mis à jour → demain part avec un meilleur contexte
- Chaque semaine : Les patterns sont distillés → le playbook grossit
- Chaque primitive : Réduit la charge cognitive future → intérêts composés
Exemple concret : Le mois dernier, j’ai remarqué que je répétais le même workflow de « refresh contexte » entre les projets : mettre à jour le LOG d’abord, puis regénérer le CONTEXT depuis le LOG. Après la troisième répétition, l’agent a créé une primitive context-refresh : une checklist avec les étapes exactes, les edge cases à surveiller et les critères de validation. Maintenant ce workflow tient en une commande. Le pattern capitalise.
Le système s’améliore que j’y prête attention ou non.
Ce n’est pas un produit fini. La transcription des notes vocales écorche parfois les termes techniques. Les heartbeats se déclenchent de temps en temps pendant la nuit. Les fichiers de contexte dérivent de la réalité plus vite que je ne le voudrais.
Mais c’est justement le point. L’architecture permet l’évolution. Le versioning Git me permet d’expérimenter sans crainte. Les agents maintiennent ce que les humains oublient.
Mouvement perpétuel
Ces trois cimetières numériques traînent toujours quelque part sur de vieux disques durs. Evernote. Roam. Notion.
Mais ce système — celui dont vous venez de lire la description — n’est pas mort. Pas parce que je le maintiens religieusement. Pas parce que j’ai une discipline surhumaine.
Parce qu’il se maintient tout seul.
Les contextes se mettent à jour pendant que je dors. Les patterns se distillent pendant que je suis occupé ailleurs. Les connexions se multiplient que je fasse gaffe ou non.
Ça ne fait que quelques mois, mais pour la première fois, mon système de savoir s’améliore avec le temps, au lieu de se dégrader.
C’est ça, la différence entre un second brain et un exosquelette.
Si vous voulez essayer
Commencez simple :
- Des fichiers markdown. Peu importe l’app.
- Un CLAUDE.md aux frontières de scope. Dites aux agents ce qui est différent ici. (Le guide d’Anthropic est un bon point de départ.)
- Une routine automatisée. Une clôture quotidienne qui met à jour les contextes.
- Observez ce qui capitalise.
Les outils spécifiques comptent moins que le pattern : donnez du contexte aux agents, gardez ce contexte frais, et laissez le système s’améliorer de lui-même.
Prêt à Automatiser Vos Opérations ?
J'écris du code. Je déploie l'infrastructure. Je forme votre équipe. Ce n'est pas du conseil. Chaque mission inclut le transfert de compétences — vous êtes propriétaires de ce que nous construisons, et votre équipe peut le maintenir. Des systèmes prêts pour la production en semaines, pas en mois.
Sites Automatisés
Agent d'audit autonome déployé sur 77 sites clients, libérant le temps des consultants pour le travail stratégique.
Entreprises Évaluées
Pipeline d'enrichissement M&A traitant les données de salons, qualifiant 155 cibles prioritaires en 2 semaines.
Visibilité Achats
Intégration ERP vers tableau de bord offrant une vue unifiée des fournisseurs et des analyses achats.